
如何用爬虫抓取电商平台数据2016年爬取热销top女装类目数据(ATTENTION-)
2022年11月18日 am2:15
•
未分类
如何用爬虫抓取电商平台数据2016年爬取热销top女装类目数据(ATTENTION-)目标获取某大型国外电商网站数据,链接本次目标是爬取热销top女装类目数据,如下:具体字段包括sku详情页标题、价格、主图等:以及所有评论(评价时间、评价星级、购买产品属性明细-颜色&尺寸、评价文字内容):具体代码如下:我这里是把数据爬取之后放到了gsheet中,用了多线程和代理。欢迎提问~
目标
获取某大型国外电商网站数据如何用爬虫抓取电商平台数据,链接
本次目标是爬取热销top女装类目数据如何用爬虫抓取电商平台数据,如下:
具体字段包括sku详情页标题、价格、主图等:
以及所有评论(评价时间、评价星级、购买产品属性明细-颜色&尺寸、评价文字内容):
具体代码如下:
# -*- coding: utf-8 -*-import mathimport reimport timeimport requestsfrom loguru import loggerfrom bs4 import BeautifulSoupfrom concurrent.futures import ThreadPoolExecutorfrom utils.request import Requestfrom utils.common import sleep2, open_gsheet, gsheet_append_rows, gsheet_append_rowclass Amazon: def __init__(self): self.headers = { 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', 'cookie': 'aws-target-data=%7B%22support%22%3A%221%22%7D; aws-target-visitor-id=1658219333848-161299.32_0; regStatus=pre-register; AMCV_7742037254C95E840A4C98A6%40AdobeOrg=1585540135%7CMCIDTS%7C19193%7CMCMID%7C83739249770090151470991008238048993563%7CMCAAMLH-1658824133%7C3%7CMCAAMB-1658824133%7CRKhpRz8krg2tLO6pguXWp5olkAcUniQYPHaMWWgdJ3xzPWQmdj0y%7CMCOPTOUT-1658226534s%7CNONE%7CMCAID%7CNONE%7CvVersion%7C4.4.0; session-id=139-5736486-7904207; i18n-prefs=USD; lc-main=zh_CN; ubid-main=131-1149456-9803809; sp-cdn="L5Z9:HK"; session-id-time=2082787201l; session-token="dW/9hnHEq1nmBVnrkKUH15nDtZkBICOXbe1BE8OEWhllybEQ+H31J6NXaSiBTzzNmOv60c8EBGA4GPla0ng0Q3RzWm6akOwxNOWeN0iFCMxh/uJ3qua0+x+5FFoIZch7r4f864Kvpaa1oOIqmGvimXVeedFsUAUTqCltiV9F3G6DGCHFRPWCYCTlxmU91tqg4NDWtLK5Z+osF5rGxyj5Oi/wzGa+1vaFx/ES6bUFZyQ="; csm-hit=tb:s-6PGAB78TGWTJMYP4B7AG|1668503449994&t:1668503450108&adb:adblk_no', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36' } self.sheet = open_gsheet('US COMMENTS', 'amazon') self.rq = Request() def request_retry(self, url): i = 0 while i < 10: try: # r = requests.get(url, headers=headers, timeout=20) r = self.rq.requests_get(url, headers=self.headers) if "Sorry, we just need to make sure you're not a robot" in r.text: print("Sorry, we just need to make sure you're not a robot")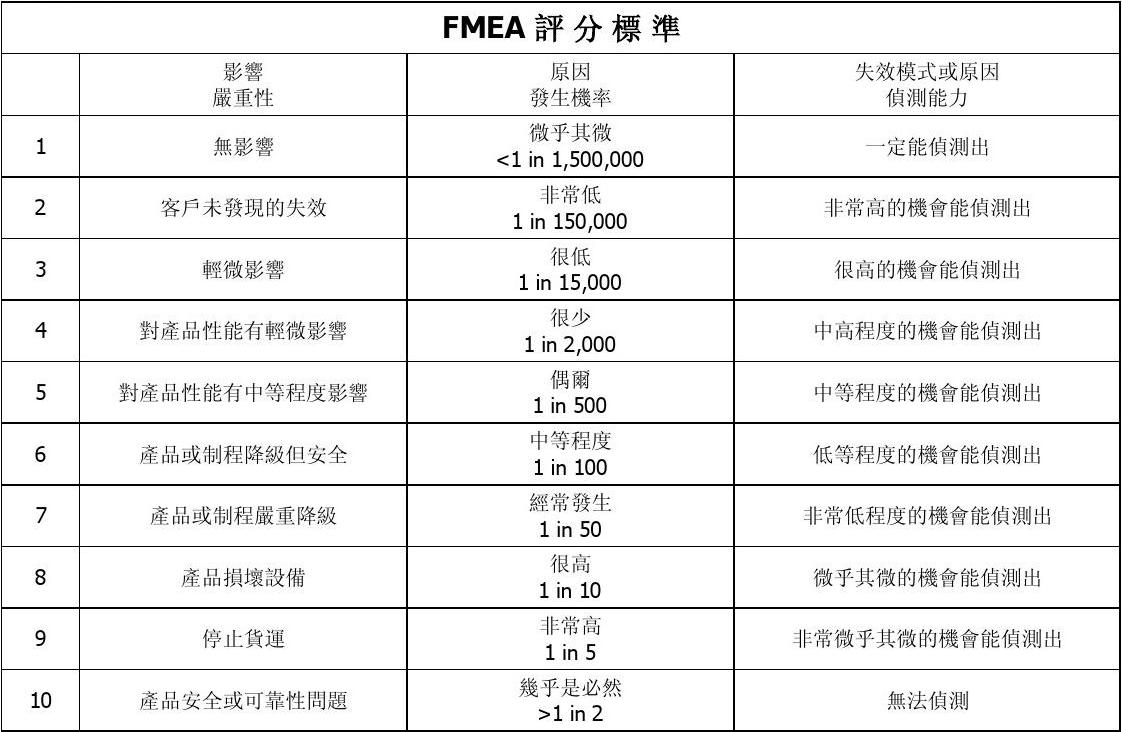

i += 1
sleep2(10)
print(f'try {i} times')
continue
if r.status_code in [404]:
i += 1
sleep2(10)
print(f'try {i} times, 404')
continue
break
except Exception as e: # 网站原因
i += 1
sleep2(10)
print(f'try {i} times, {e.args}')
else:
raise
return r
def treat_comment_page(self, id, page):
logger.info(f'page: {page}')
url = f'https://www.amazon.com/product-reviews/{id}/ref=cm_cr_getr_d_paging_btm_next_{page}?ie=UTF8&reviewerType=all_reviews&pageNumber={page}'
r = self.request_retry(url)
# r = self.rq.requests_get(url, headers=self.headers)
# print(r.status_code, r.text[:1000])
soup = BeautifulSoup(r.text, 'lxml')
comments_tag = soup.select('.a-section.review')
comments = []
for comment_tag in comments_tag:
comment_time = comment_tag.select('.a-row .review-date')[0].text.strip()[3:].strip() # .split(' ')[0]
try:
comment_style = comment_tag.select('.a-size-mini.a-link-normal.a-color-secondary')[0].text.strip()
except:
comment_style = ''
comment_content = comment_tag.select('[data-hook="review-body"]')[0].text.replace('n', '').strip()
comment_star = comment_tag.select('[data-hook="review-star-rating"] .a-icon-alt')[0].text.strip().split(',')[0][:-2].strip()
print(comment_time, comment_star, comment_style, comment_content)
comment_data = ['', '', '', '', '', comment_time, comment_star, comment_style, comment_content]
comments.append(comment_data)
gsheet_append_rows(self.sheet, comments)
def parse_exception(self, obj):
res = obj.result()
if res:
print(res)

def more_comment(self, id):
# 先从第二页获取评论总数
logger.info('page: 2')
url = f'https://www.amazon.com/product-reviews/{id}/ref=cm_cr_arp_d_paging_btm_next_2?ie=UTF8&reviewerType=all_reviews&pageNumber=2'
r = self.request_retry(url)
soup = BeautifulSoup(r.text, 'lxml')
comments_tag = soup.select('.a-section.review')
comments = []
for comment_tag in comments_tag:
comment_time = comment_tag.select('.a-row .review-date')[0].text.strip()[3:].strip() # .split(' ')[0]
try:
comment_style = comment_tag.select('.a-size-mini.a-link-normal.a-color-secondary')[0].text.strip()
except:
comment_style = ''
comment_content = comment_tag.select('[data-hook="review-body"]')[0].text.replace('n', '').strip()
comment_star = comment_tag.select('[data-hook="review-star-rating"] .a-icon-alt')[0].text.strip().split(',')[0][:-2].strip()
print(comment_time, comment_star, comment_style, comment_content)
comment_data = ['', '', '', '', '', comment_time, comment_star, comment_style, comment_content]
comments.append(comment_data)
gsheet_append_rows(self.sheet, comments)
total_comment = int(soup.select('[data-hook="cr-filter-info-review-rating-count"]')[0].text.strip().split('总评分,')[-1].replace('带评论', '').replace(',', '').strip())
print('total_comment', total_comment)
total_page = math.ceil(total_comment / 10)
exec = ThreadPoolExecutor(max_workers=3)
for page in range(3, total_page + 1):
exec.submit(self.treat_comment_page, id, page).add_done_callback(self.parse_exception)
exec.shutdown(wait=True)
def detail(self, ue_sid, id, referer):
headers = self.headers.copy()
headers.update({'referer': referer})
url = f'https://www.amazon.com/dp/{id}/{ue_sid}?psc=1'
print(url)
# response = self.request_retry(url, headers)
response = self.rq.requests_get(url, headers=headers)
print(response.status_code, response.text[:1000])
soup = BeautifulSoup(response.text, 'lxml')
title = soup.select('#productTitle')[0].text.strip()
price = soup.select('.a-price span')[0].text.strip()
img_url = soup.select('.imgTagWrapper img')[0].attrs['src']
img_url = f'=IMAGE("{img_url}")'
category = ''
comments_tag = soup.select('#cm-cr-dp-review-list .a-section.review.aok-relative')
sku_data = [title, price, img_url, category, url]
gsheet_append_row(self.sheet, sku_data)
comments = []
print(title, price, img_url, category)
for comment_tag in comments_tag:
comment_time = comment_tag.select('.a-row .review-date')[0].text.strip()[3:].strip() # .split(' ')[0]
comment_style = comment_tag.select('[data-hook="format-strip-linkless"]')[0].text.strip()
comment_content = comment_tag.select('.a-expander-content span')[0].text.strip()
comment_star = comment_tag.select('.a-icon-alt')[0].text.strip().split(',')[0][:-2].strip()
print(comment_time, comment_star, comment_style, comment_content)
comment_data = ['', '', '', '', '', comment_time, comment_star, comment_style, comment_content]
comments.append(comment_data)
gsheet_append_rows(self.sheet, comments)
self.more_comment(id)
def treat_one_page(self, url, page):
url = url.split('=')[0] + '=' + str(page)
response = self.request_retry(url)
ue_sid_pattern = re.compile("ue_sid = '(.*?)'")
id_pattern = re.compile('"id":"(.*?)",', re.S)
ue_sid = re.search(ue_sid_pattern, response.text).group(1)
ids = re.findall(id_pattern, response.text)
print(ue_sid, ids)
for idx, id in enumerate(ids):
logger.info(f'{idx}/{len(ids)} {id}')
self.detail(ue_sid, id, url)
break
def main(self):
urls = ['https://www.amazon.com/-/zh/Best-Sellers-/zgbs/fashion/1040660/?pg=1'] # top女装目录链接
for url in urls:
# 取前2页
for page in range(1, 2):
logger.info(f'url: {url}, page:{page}')
self.treat_one_page(url, page)
if __name__ == '__main__':
a = Amazon()
a.main()
我这里是把数据爬取之后放到了gsheet中,用了多线程和代理。欢迎提问~
【ATTENTION】仅技术交流,勿作其他用途
赞 (0)
如何做公众号入驻公众号一个星期后我赚到了自己的第一桶金
« 上一篇
2022年11月18日 am2:12
内容营销产品【干货】内容营销实操经验之一个高性价比
下一篇 »
2022年11月18日 am2:16
相关推荐
-
外贸全网营销方案 广东0代运营,怎么选择靠谱的合作机构?
-
销售链接活动策划案出版日期:2022年1月开本:16开出版社:经济管理出版社策划型原案例理论建构
-
大学 新媒体营销专业课程 京东大学众创学院创业加速计划海南首期班课程开课28名行业精英齐聚一堂
-
孕妇防蚊产品品牌润本老牌驱蚊贴品牌推荐:婴姿坊纯天然植物精油24小时
-
免费网址注册免费域名要不要?教你获取免费的域名【申请教程】
-
小米手机新媒体营销方式整合营销全面系统阐述了整合营销传播理论,认为整合营销来传递品牌
-
数据挖掘实战数据和代码均已附在文末,需要自取。
-
保健酒招商加盟靠一瓶15元的小酒年赚上百亿,打败茅台五粮液
-
品牌推广小马识途营销机构的营销顾问谈谈中小企业如何做好网络品牌推广
-
经纬中国大众汽车集团(中国)执行副总裁刘云峰刘云峰(受访者供图)(图)
本文内容由互联网用户贡献,该文观点仅代表作者本人。本站不拥有所有权,不承担相关法律责任。如发现有侵权/违规的内容, 联系QQ304797345,本站将立刻清除。
